量化投资
300多个选股因子,真正值得盯住的只有这4件事
面对数百个选股因子,真正需要判断的是有效性、稳定性、独立性与可交易性。
300多个选股因子,真正值得盯住的只有这4件事
因子不是“稳赚公式”,而是一把衡量股票特征的尺子。真正决定结果的,往往不是你找到了多少因子,而是它有没有逻辑、是否稳定、能否交易,以及失效时你能不能及时发现。
很多人第一次接触量化选股,会被一长串术语劝退:
价值、成长、质量、动量、反转、波动率、流动性、情绪、高频、机器学习……
看起来每一个都能解释市场,每一个都像通往超额收益的钥匙。
但现实是,学术研究已经记录了数百个与收益相关的特征。因子越多,越容易出现“从历史数据里碰巧挖到规律”的问题。一个回测漂亮的公式,可能只是在解释过去,而不是预测未来。
所以,研究选股因子的核心问题不是:
“还有什么新因子?”
而是:
“这个因子为什么有效、什么时候有效、扣掉成本后还能不能用?”
这篇文章不打算再堆一份因子百科,而是用一套更接近实战的框架,讲清楚普通投资者和量化研究者真正应该关注的四件事。
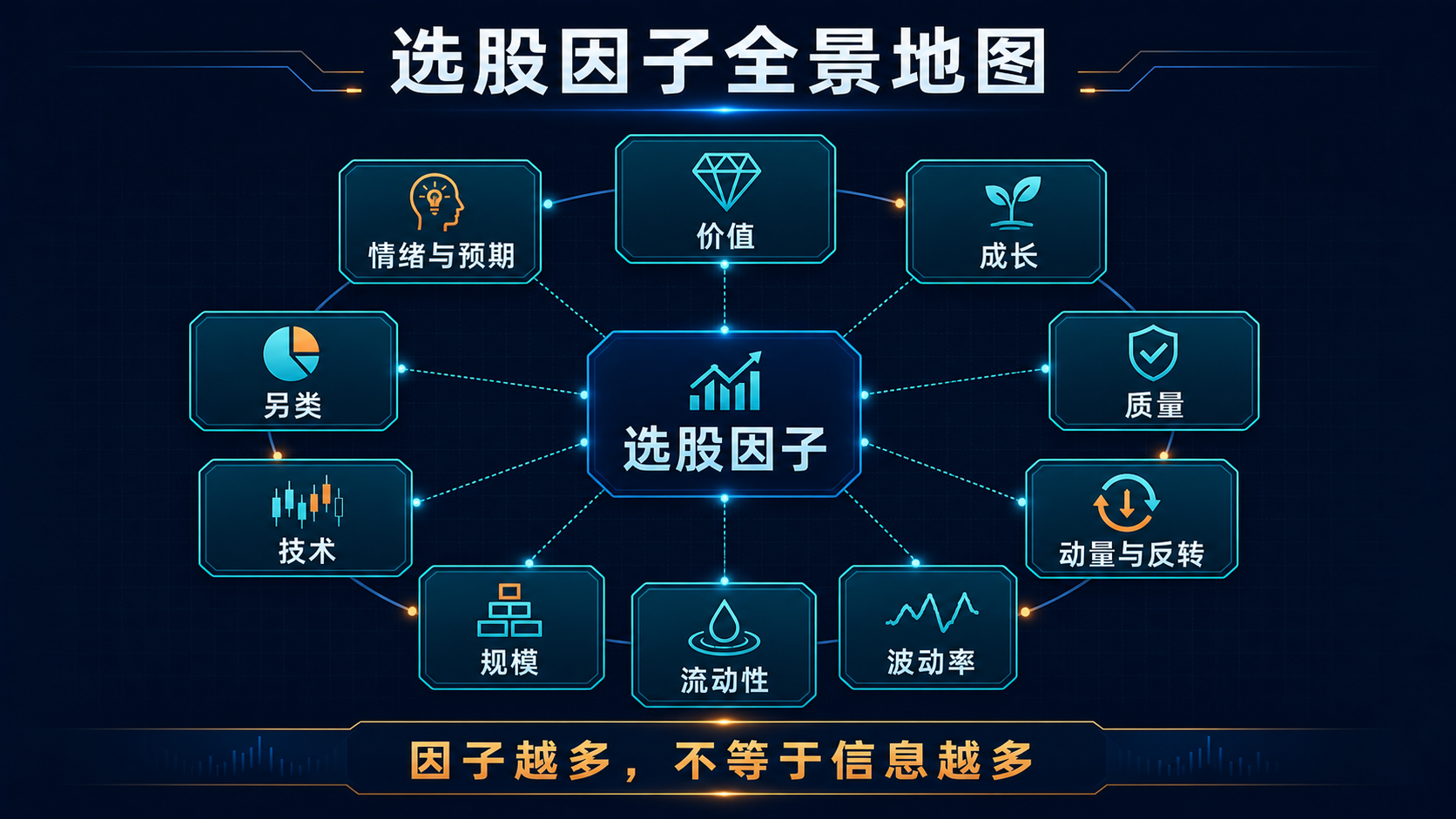
一、因子到底是什么?
可以把因子理解为一把“给股票打分的尺子”。
例如:
- 市盈率低,价值因子得分可能更高;
- 盈利增速快,成长因子得分可能更高;
- ROE高、负债率低,质量因子得分可能更高;
- 近期涨幅落后,反转因子可能认为它更有修复空间。
研究者会在同一天给一批股票打分,再观察高分组和低分组未来的收益是否存在稳定差异。
如果这种差异长期存在,并且有合理解释、能够交易,它才可能成为一个有价值的选股因子。
这里有一个很重要的区别:
因子描述的是“统计上更可能”,不是“某只股票一定会涨”。
即使一个因子长期有效,也可能连续数月甚至数年失灵。因子投资赚的不是确定性,而是大量样本中略微偏向自己的概率优势。
二、数百个因子,可以先看成10个家族
市场上的因子名称很多,但大部分可以归入以下10类。
| 因子家族 | 它在问什么 | 常见指标 |
|---|---|---|
| 价值 | 这家公司是否卖得便宜? | PE、PB、股息率、现金流收益率 |
| 成长 | 收入和利润是否在加速? | 营收增速、利润增速、预期修正 |
| 质量 | 赚到的钱是否真实、可持续? | ROE、毛利率、负债率、应计利润 |
| 动量与反转 | 趋势会延续,还是会回归? | 近期收益率、52周新高、短期反转 |
| 波动率 | 股价运行是否平稳? | 历史波动率、特质波动率、最大回撤 |
| 流动性 | 买卖是否方便,冲击成本多大? | 换手率、成交额、Amihud非流动性 |
| 规模 | 大公司和小公司谁更占优? | 总市值、流通市值、自由流通市值 |
| 技术 | 价格和成交量呈现什么形态? | 均线偏离、量价背离、筹码分布 |
| 情绪与预期 | 市场共识正在变好还是变差? | 分析师预期、融资余额、新闻情绪 |
| 另类数据 | 传统财报之外还有什么信息? | 高频订单、供应链、文本、卫星数据 |
这张表的作用不是让你把10类因子全部塞进模型,而是帮助你分辨:
不同名字的因子,可能在重复表达同一件事。
例如,低PE、低PB、高股息率都可能带来相似的价值暴露;近期涨幅、均线偏离和52周新高接近度,也可能共同暴露于趋势行情。
因子数量增加,不代表信息一定增加。有时只是把同一个观点说了很多遍。
三、做A股因子研究,不能照搬海外结论
同一个因子,在不同市场、不同股票池和不同时间段中,表现可能完全不同。
A股尤其需要关注四个现实约束。
1. 短期反转值得单独检验
海外市场常讨论中期动量,也就是“过去表现好的股票,未来一段时间继续表现较好”。
但在不少A股实证和特定时间窗口中,短期反转表现得比传统中期动量更明显。涨跌停制度、事件驱动和情绪波动,都可能影响信号的方向与持续时间。
这不代表“跌得多就应该买”。真正可用的反转因子,通常还需要排除基本面恶化、流动性枯竭和重大负面事件。
2. 小盘溢价背后藏着流动性风险
小市值股票有时能提供明显超额收益,但这种收益并不是免费的。
当市场风格切换或流动性骤降时,小微盘股票可能同时出现成交困难、价格冲击放大和组合集中回撤。回测里轻松完成的调仓,实盘中未必能够成交。
因此,研究规模因子不能只看收益,还要同时检查:
- 日均成交额是否足够;
- 组合容量有多大;
- 极端行情中能否退出;
- 剔除微盘股后,收益是否仍然存在。
3. 多头有效,比“多空组合漂亮”更重要
很多论文用“买入高分组、卖空低分组”衡量因子收益。
但对大多数A股投资者来说,稳定做空并不现实。如果一个因子的收益主要来自“低分股票跌得更多”,而高分股票本身并没有明显超额收益,那么它在多头组合中的价值会大打折扣。
所以测试因子时,不能只看多空收益,还要单独观察高分组相对基准的表现。
4. 政策与交易制度会改变因子表现
量化模型擅长处理可重复的数据规律,却很难提前刻画政策变化、监管调整和交易制度冲击。
这意味着模型之外必须保留风险开关:限制单一风格暴露、设置流动性门槛,并在市场结构发生变化时降低对历史规律的信任。
四、真正决定成败的,是因子研究流水线
一个因子从“听起来有道理”到“能够进入组合”,至少要经过八道关。
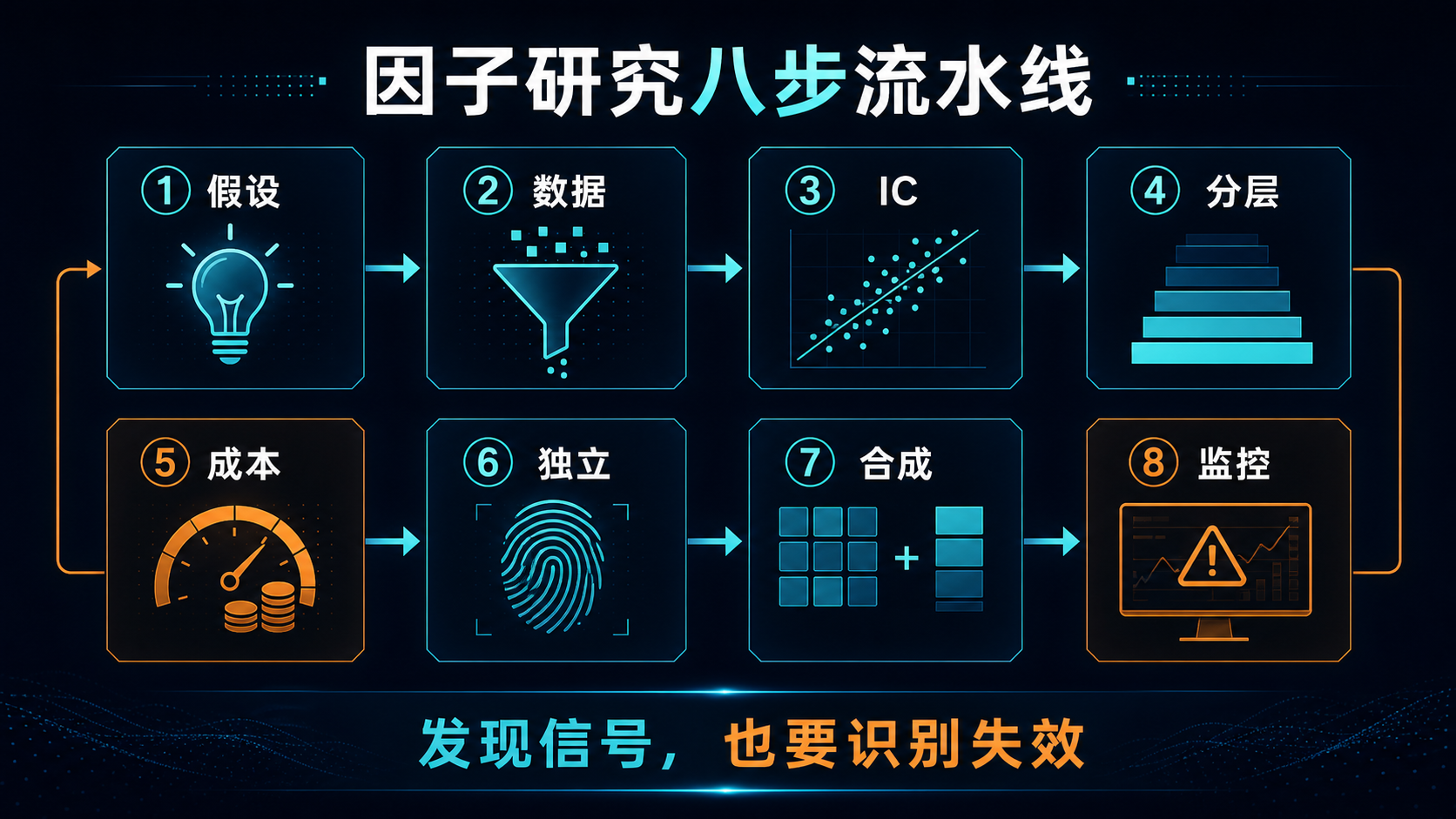
第一步:提出可以解释的假设
先回答一个问题:为什么这个特征可能预测收益?
常见解释通常来自三类:
- 风险补偿:承担了别人不愿承担的风险,因此获得更高回报;
- 行为偏差:投资者反应过度或反应不足,导致错误定价;
- 市场摩擦:交易成本、卖空限制或信息获取差异,使价格不能立刻修正。
如果完全说不清经济逻辑,回测结果越漂亮,越应该警惕数据挖掘。
第二步:先清洗数据,再计算因子
因子研究最容易被低估的环节,是数据预处理。
常见步骤包括:
- 剔除ST、长期停牌、新股等异常样本;
- 处理缺失值,避免引入未来信息;
- 去极值,降低少数异常值的影响;
- 标准化,让不同量纲的因子可以比较;
- 做行业和市值中性化,避免把行业行情误认成选股能力。
例如,一个“高盈利”组合可能集中在某个强势行业。如果不做行业中性化,你以为自己找到了盈利因子,实际上只是押中了行业。
第三步:用IC判断方向和稳定性
IC,也就是信息系数,通常用来衡量:
今天的因子排名,与未来收益排名有多一致。
IC为正,意味着因子分数越高,未来收益往往越高;IC为负,则意味着方向相反。
但比单期IC更重要的是:
- 长期平均IC是否稳定;
- 不同年份是否方向一致;
- 在不同指数和行业中是否有效;
- 信号多久衰减;
- 结果是否依赖少数极端月份。
不要把某个固定阈值当成通行证。可交易性、股票池和调仓频率不同,合理标准也不同。
第四步:看分层回测,而不是只看平均数
把股票按照因子得分分成5组或10组,观察每组未来收益。
一个更可信的因子,通常会呈现较清晰的单调关系:得分越高,组合表现越好,或者稳定地越差。
如果只有最极端的一组有效,中间各组毫无规律,就要判断它究竟是稳定信号,还是少数异常样本造成的结果。
第五步:把交易成本和容量算进去
回测收益不是实盘收益。
高换手因子可能在扣除手续费、滑点和冲击成本后失去优势;小盘因子则可能随着资金规模增大迅速失效。
至少要做三次压力测试:
- 提高交易成本后,收益是否仍然存在;
- 延迟一天成交后,收益是否仍然存在;
- 剔除低流动性股票后,收益是否仍然存在。
第六步:检查它是否只是旧因子的“换皮”
新因子与现有因子高度相关,未必能为组合增加信息。
可以通过相关性分析、回归残差或正交化,检查它在剔除价值、规模、行业等常见暴露后,是否仍然有效。
第七步:从简单合成开始
多个因子组合时,复杂方法不一定更好。
| 合成方法 | 优点 | 主要风险 |
|---|---|---|
| 等权 | 简单、透明、稳健 | 忽略因子强弱变化 |
| IC或ICIR加权 | 根据历史表现动态调整 | 对窗口选择敏感 |
| 优化模型 | 可控制风险与约束 | 容易过拟合,解释成本高 |
| 机器学习 | 能捕捉非线性与交互 | 对数据、验证和监控要求更高 |
对大多数团队而言,等权组合是一个很好的基线。只有当复杂方法在严格样本外测试中持续胜出,才值得承担额外复杂度。
第八步:上线后持续监控
因子不是研发完成就可以永久使用的产品。
上线后需要持续观察:
- IC和分层收益是否下降;
- 因子之间的相关性是否突然升高;
- 换手率和交易成本是否上升;
- 收益是否越来越集中于少数股票;
- 当前市场是否进入因子不擅长的环境。
一个成熟的因子系统,必须同时具备“发现信号”和“识别失效”的能力。
五、用四个维度,筛掉大多数“伪Alpha”
面对一个新因子,可以用下面四个问题快速判断。
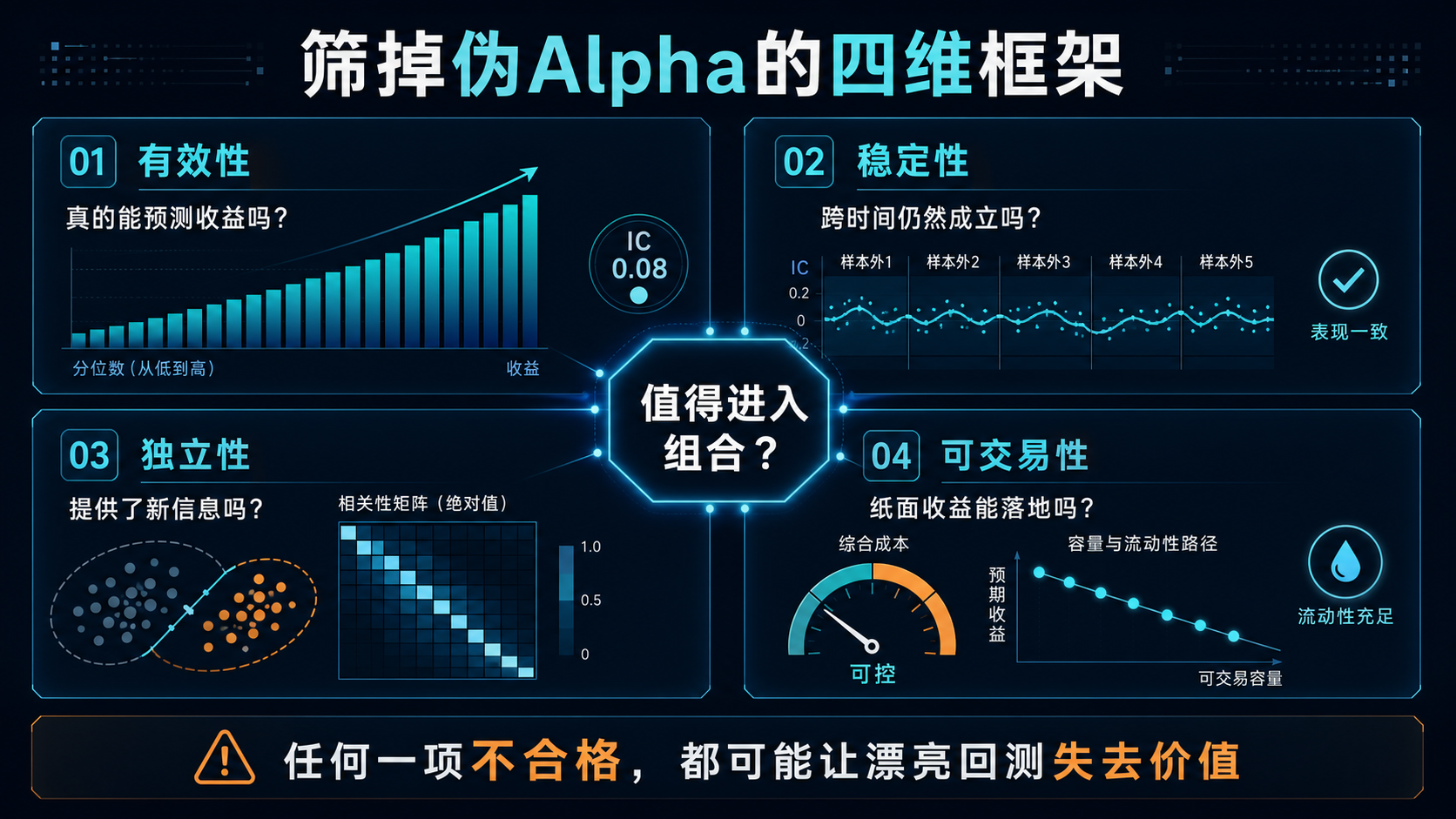
1. 有效性:它真的能预测未来收益吗?
看IC、分层收益和相对基准超额,但必须使用样本外数据,防止只解释历史。
2. 稳定性:它是否只在某一段时间有效?
拆分年份、市场阶段、行业和股票池。如果结论只依赖一个牛市或少数月份,可信度就很有限。
3. 独立性:它提供了新信息吗?
检查它是否只是价值、规模、行业或动量暴露的另一种表达。
4. 可交易性:纸面收益能变成真实收益吗?
检查换手率、流动性、容量、成本,以及A股多头端是否真正有效。
这四个维度中,任何一项明显不合格,都可能让漂亮的回测失去实战价值。
六、为什么很多因子会失效?
因子通常会经历一个生命周期:
发现 → 扩散 → 资金涌入 → 拥挤 → 收益压缩 → 失效或进化
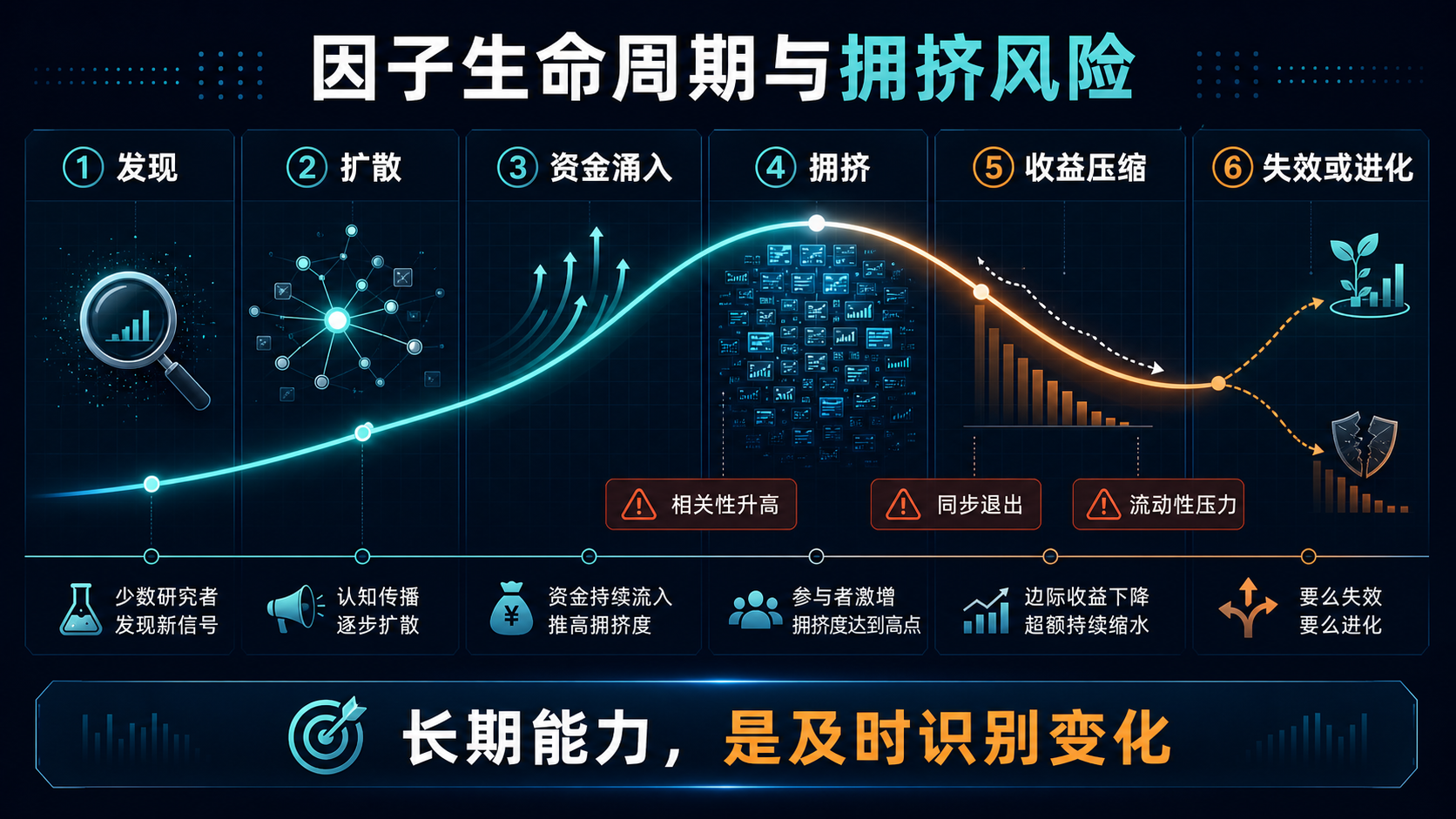
当越来越多资金使用相似信号时,原本的定价偏差会被提前交易,未来收益自然下降。更危险的是,许多策略可能在同一时间买入和卖出相似股票。
一旦市场反转,大家同时退出,就会放大回撤。
判断因子是否拥挤,可以关注:
- 使用类似策略的资金规模是否快速增长;
- 因子收益是否下降、波动是否上升;
- 因子之间的相关性是否突然提高;
- 交易是否集中在低流动性股票;
- 回撤时是否出现同步抛售。
真正长期有效的能力,不是找到一个永不失效的公式,而是持续更新假设、验证数据,并在环境变化时及时降权。
七、机器学习能否找到更好的因子?
机器学习确实扩展了因子研究的边界。
树模型、神经网络和图神经网络可以捕捉传统线性模型难以发现的非线性关系与变量交互;大语言模型也开始参与假设生成、代码实现、文本信息提取和研究流程自动化。
但机器学习没有消灭因子研究最难的问题,反而把它们放大了:
- 特征越多,数据泄漏和过拟合风险越高;
- 模型越复杂,越难解释失效原因;
- 回测越自动化,越容易批量制造“看起来有效”的结果;
- 训练成本和数据成本更高,实盘监控也更困难。
因此,评价AI因子时,不应只问“回测提升了多少”,还要问:
- 是否严格区分训练集、验证集和测试集;
- 是否避免使用未来数据;
- 扣除交易成本后是否仍有增量;
- 换一个时间段或股票池是否还能成立;
- 模型失效时能否被发现和解释。
AI可以成为更强的研究工具,但不能替代研究纪律。
八、普通投资者如何使用因子思维?
你不一定要搭建完整量化系统,才能从因子研究中受益。
在分析一只股票或一个组合时,可以依次问:
- 价值:当前价格已经透支了多少预期?
- 成长:收入和利润增长是否真实、可持续?
- 质量:现金流、负债和盈利稳定性如何?
- 情绪:市场是否过度乐观或过度悲观?
- 风险:流动性、波动和回撤是否可承受?
- 拥挤:这是不是所有人都在交易的共识?
然后再做三次反向检查:
- 如果去掉行业行情,这家公司还优秀吗?
- 如果市场风格切换,这个逻辑还能成立吗?
- 如果明天不能顺利卖出,我还愿意持有吗?
这比寻找一个神奇指标,更接近因子投资真正有价值的地方。
结语:好因子不是被“发现”的,而是被反复证伪后留下的
数百个因子并不意味着市场上有数百条稳定赚钱的捷径。
一个值得进入组合的因子,至少需要经过经济逻辑、数据清洗、样本外检验、交易成本和持续监控的共同考验。
最后记住四句话:
有效,不等于稳定。
稳定,不等于独立。
独立,不等于可交易。
历史可交易,也不等于未来不会失效。
量化研究的价值,不是让投资变得确定,而是让每一个判断更可验证、每一次犯错更容易被发现。
参考资料
- Harvey, Liu & Zhu, …and the Cross-Section of Expected Returns:讨论因子数量增长与多重检验问题
- Gu, Kelly & Xiu, Empirical Asset Pricing via Machine Learning:研究机器学习在资产定价中的应用
- Fama & French:三因子、五因子资产定价框架
- Microsoft Qlib、Alphalens:常用量化研究与因子分析工具
- 华泰证券金融工程,2026年4月《高频特征参数化:分钟级可解释因子挖掘框架》
风险提示:本文用于研究方法交流,不构成任何投资建议。因子历史表现不代表未来收益,回测结果可能受到样本选择、交易成本、流动性和模型设定影响。